
When reading about Machine Learning, the majority of the material you’ve encountered is likely concerned with classification problems. You have a certain input, and the ML model tries to figure out the features of that input. For example, a classification model can decide whether an image contains a cat or not.
What about the other way around when you want to create data with predefined features? These problems are solved by generation models, however, by nature, they are more complex. The two main approaches are Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs). We’ve covered GANs in a recent article which you can find here. Today we’ll be breaking down VAEs and understanding the intuition behind them.
What is an Autoencoder?
We’ll start with an explanation of how a basic Autoencoder (AE) works in general. When building any ML model, the input you have is transformed by an encoder into a digital representation for the network to work with. This is done to simplify the data and save its most important features. Well, an AE is simply two networks put together — an encoder and a decoder. The goal of this pair is to reconstruct the input as accurately as possible. The encoder saves a representation of the input after which the decoder builds an output from that representation.

At first, this might seem somewhat counterproductive. Why go through all the hassle of reconstructing data that you already have in a pure, unaltered form? The point is that through the process of training an AE learns to build compact and accurate representations of data. It figures out which features of the input are defining and worthy of being preserved.
However, apart from a few applications like denoising, AEs are limited in use. Their main issue for generation purposes comes down to the way their latent space is structured. It isn’t continuous and doesn’t allow easy extrapolation. Encoded vectors are grouped in clusters corresponding to different data classes and there are big gaps between the clusters. Why is this a problem? When generating a brand new sample, the decoder needs to take a random sample from the latent space and decode it. If the chosen point in the latent space doesn’t contain any data, the output will be gibberish.

Variational Autoencoders to the Rescue
Variational Autoencoders are designed in a specific way to tackle this issue — their latent spaces are built to be continuous and compact. During the encoding process, a standard AE produces a vector of size N for each representation. One input — one corresponding vector, that’s it. A VAE, on the other hand, produces 2 vectors — one for mean values and one for standard deviations. Instead of a single point in the latent space, the VAE covers a certain “area” centered around the mean value and with a size corresponding to the standard deviation. This gives our decoder a lot more to work with — a sample from anywhere in the area will be very similar to the original input.
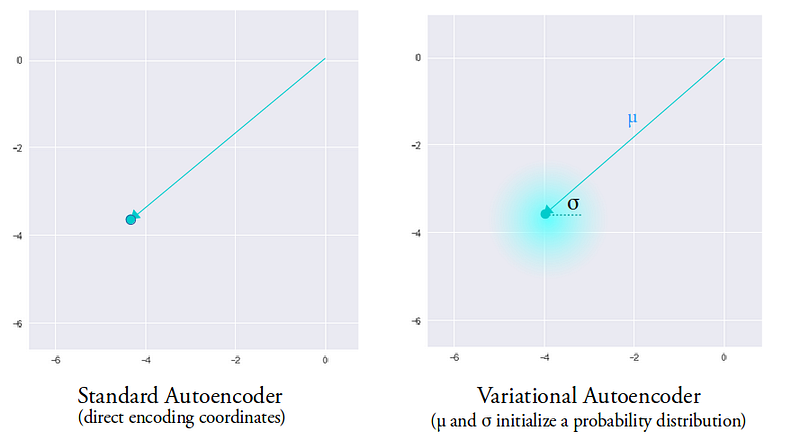
This gives us variability at a local scale. However, we still have the issue of data grouping into clusters with large gaps between them. In order to solve this, we need to bring all our “areas” closer to each other. Far enough away to be distinct, but close enough to allow easy interpolation between different clusters. This is achieved by adding the Kullback-Leibler divergence into the loss function.

This divergence is a way to measure how “different” two probability distributions are from each other. By minimizing it, the distributions will come closer to the origin of the latent space.
Combining the Kullback-Leibler divergence with our existing loss function we incentivize the VAE to build a latent space designed for our purposes. Data will still be clustered in correspondence to different classes, but the clusters will all be close to the center of the latent space. Now we freely can pick random points in the latent space for smooth interpolations between classes.
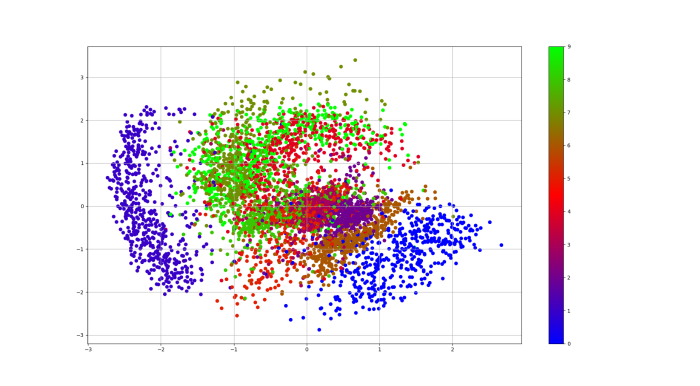
Generating New Data
Creating smooth interpolations is actually a simple process that comes down to doing vector arithmetic. Suppose that you want to mix two genres of music — classical and rock. Once your VAE has built its latent space, you can simply take a vector from each of the corresponding clusters, find their difference, and add half of that difference to the original. Once that result is decoded, you’ll have a new piece of music! And because of the continuity of the latent space, we’ve guaranteed that the decoder will have something to work with.
This can also be applied to generate and store specific features. Suppose you have an image of a person with glasses, and one without. If you find the difference between their encodings, you’ll get a “glasses vector” which can then be stored and added to other images. What’s cool is that this works for diverse classes of data, even sequential and discrete data such as text, which GANs can’t work with.
VAEs for Anomaly Detection
Apart from generating new genres of music, VAEs can also be used to detect anomalies. Anomalies are pieces of data that deviate enough from the rest to arouse suspicion that they were caused by a different source. Anomaly detection is applied in network intrusion detection, credit card fraud detection, sensor network fault detection, medical diagnosis, and numerous other fields. If you’re interested in learning more about anomaly detection, we talk in-depth about the various approaches and applications in this article.
Traditional AEs can be used to detect anomalies based on the reconstruction error. Initially, the AE is trained in a semi-supervised fashion on normal data. Once the training is finished and the AE receives an anomaly for its input, the decoder will do a bad job of recreating it since it has never encountered something similar before. This will result in a large reconstruction error that can be detected.
With VAEs the process is similar, only the terminology shifts to probabilities. Initially, the VAE is trained on normal data. For testing, several samples are drawn from the probabilistic encoder of the trained VAE. Then, for each sample from the encoder, the probabilistic decoder outputs the mean and standard deviation parameters. Using these parameters, the probability that the data originated from the distribution is calculated. The average probability is then used as an anomaly score and is called the reconstruction probability. Data points with high reconstruction probability are classified as anomalies.
A major benefit of VAEs in comparison to traditional AEs is the use of probabilities to detect anomalies. Reconstruction errors are more difficult to apply since there is no universal method to establish a clear and objective threshold. With probabilities the results can be evaluated consistently even with heterogeneous data, making the final judgment on an anomaly much more objective.
VAEs by RealityEngines
Variational Autoencoders are just one of the tools in our vast portfolio of solutions for anomaly detection. RealityEngines provides you with state of the art Fraud and Security solutions such as:
- Account Takeover and Defense. Shield your customers by preventing malicious insiders, bots, and bad actors from taking over accounts.
- Cloud Spend Alerts Track runaway cloud spend by optimize your spend.
- Intelligent Threat Detection. Continuously monitor your environment for malicious activity and stop breachers in their tracks.
Setup is simple and takes only a few hours — no Machine Learning expertise required from your end. Be sure to check out our website for more information.
- Improving Open-Source LLMs – Datasets, Merging and Stacking - January 11, 2024
- Open Source LLMs, Fine-Tunes and RAG Based Vector Store APIs - October 19, 2023
- Closing the Gap to Closed Source LLMs – 70B Giraffe 32k - September 25, 2023