
Like many other Machine Learning concepts, meta-learning is an approach akin to what human beings are already used to doing. Meta-learning simply means “learning to learn.” Whenever we learn any new skill there is some prior experience we can relate to, which makes the learning process easier. The same goes for AI, and meta-learning has been an increasingly popular topic over the last several years. The goal isn’t to take one model and focus on training it on one specific dataset. Rather, a model can gather previous experience from other algorithm’s performance on multiple tasks, evaluate that experience, and then use that knowledge to improve its performance.
The biggest challenge of meta-learning is taking abstract “experience” and structuring it in a systemic, data-driven way. Depending on the type of meta-data employed a meta-learning model can be broadly put into three categories: learning from previous model evaluations, learning from task properties, and learning from the prior models themselves.
Model Evaluations
Suppose we have data on how a set of learning algorithms has performed on certain tasks. The input required for the meta-learner will look like this:
- A set of known tasks.
- Configurations for the learning algorithms (hyperparameters, pipeline components, network architecture components).
- A set of evaluations for each configuration’s performance on each task — accuracy, for example.
Using this terminology we can state what we want from our meta-learner. Training on the data given above, we want to recommend optimal configurations for new tasks that come our way.
Task-Independent Recommendations
In a scenario where we don’t have knowledge of any evaluations on new tasks, we can still run our meta-learner and receive a set of recommended configurations. This way we will achieve a ranking of configurations based on accuracy, training time, and task-specific success rates.
Designing a better configuration space
Again, we can work independently from knowledge about new tasks, but this time focusing on optimizing the space of our configurations. By narrowing down the relevant regions that need to be explored, this can significantly speed up the search for optimal models. For example, one paper describes a ranking of hyperparameters by the amount of variance they introduce into an algorithm’s performance.
Configuration transfer
If there is a specific new task that we want to provide recommendations on, we can do that by comparing that task with the ones from our training set. Configurations that performed well on similar tasks would be more likely to give better results on the new one presented to us. Task similarity can be assessed by using relative landmarks, surrogate models, warm-started multi-task learning, and other techniques.

Learning curves
The last model evaluation approach worth mentioning is concerned with learning curves. We can learn from the training process itself, and not just the end result. When running an evaluation on a new task we can pause the process and check how quickly our configuration is learning and make the decision to continue the training or not. This allows us to significantly speed up the search for good configurations.
Task Properties
Instead of evaluating the configurations, we can extract a rich source of meta-data from the tasks themselves. Each task can be described with a vector of associated meta-features, which most commonly include skewness, class entropy, volume of overlap, and dozens of other parameters. Instead of manually defining a list of meta-features, we can learn a joint representation for groups of tasks. One approach involves constructing a binary meta-feature for every pair of configurations, indicating whether the first configuration of the pair outperformed the other. Here are some of the ways meta-features can be used for meta-learning.
Warm-starting optimization
What’s great about meta-features is how easily they lend themselves as a way to estimate task similarity. We can find the prior tasks most similar to a new one and pick the most promising configuration for each of them. For example, this can be used to further start a genetic search algorithm.
Building meta-models
Meta-models are an excellent tool for algorithm selection and hyperparameter recommendation. Given the meta-features of a new task, we can build a meta-model that will learn the relationship between meta-features and specific configurations. Our meta-model will then output the most useful configurations for any new tasks that we want.
Setting up pipelines
Creating the optimal pipeline for machine learning tasks is important, however, the task adds a number of configuration parameters. In this case, learning from prior experience is even more essential in order to not get swamped. We can control the search space by imposing strict rules for our pipeline defined by hyperparameters, and then use the most promising ones to warm-start optimization.
Save time on parameter tuning
Another application worth mentioning is how meta-models can predict whether it is worth tuning specific algorithms in the first place. Given the meta-features of a new task, we can estimate how much improvement to expect from a specific algorithm and compare it with the time investment involved. This is a good way of saving time on configurations that will take a lot of time to train but won’t be worth it in terms of the final performance.
Prior Models
Finally, we can take the structure and learned parameters of the models themselves as our meta-data. Our meta-learner will learn how to train new models based on given tasks and the models that have been optimized for them (defined by model parameters and their configurations).
Transfer learning
Transfer learning once again takes the concept of task similarity as its core. When we want to create a new model for a target task, we can use models trained on similar tasks as starting points. This approach is widely applicable and has been successfully used for kernel methods, parametric Bayesian models, Bayesian networks, clustering, and reinforcement learning. Neural networks are exceptionally well suited for transfer learning.
Neural Networks
One of the earliest approaches to meta-learning used Recurrent Neural Networks (RNNs) capable of modifying their own weights. They would use their own parameters as inputs, experiment with how those weights affected the error, and learned how to modify them in response. Later works used reinforcement learning across tasks to adapt the search strategy or the learning rate for gradient descent depending on the task in question.
Few-Shot Learning
Learning with only a small training data set is a hot topic in ML. There are often cases when you have lots of training data for one task, but lack sufficient data for a new but similar task. This meta-learning problem is called few-shot learning. By learning a common feature representation of all the known tasks, our new model can be guided through the optimization of model parameters which speeds up the training process significantly.
Non-supervised learning
All of the above examples involve supervised or semi-supervised scenarios. However, meta-learning can definitely go beyond. It has been successfully applied to reinforcement learning, active learning, density estimation, and item recommendation.
Meta-Learning Applications
Because of its rather abstract nature, meta-learning can be applied to many different machine learning problems.
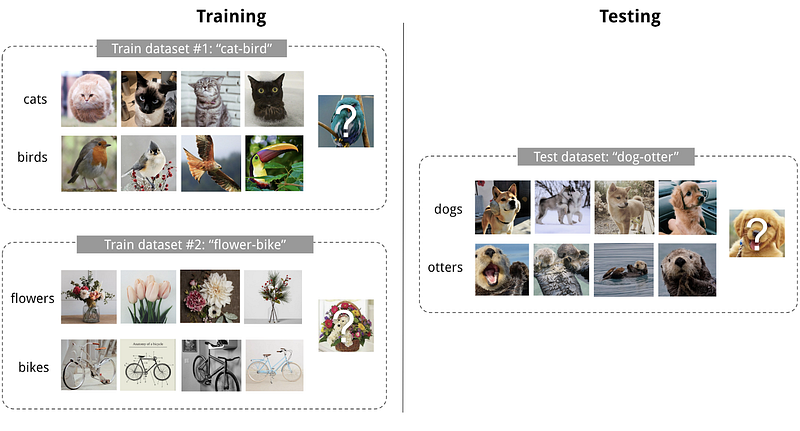
- Computer Vision and Graphics. Meta-learning has a high impact on few-shot learning, which holds a lot of promise for dealing with challenges in computer vision. Methods can be applied for classification, object detection, landmark prediction, image generation, and other purposes.
- Meta Reinforcement Learning and Robotics. Reinforcement learning often suffers from sample inefficiency due to sparse rewards and high variance in its optimization algorithms. On the other hand, RL is naturally suited to exploit cases with prior experience, such as locomotion, navigating in different environments, and driving different cars.
- Language and Speech. Popular demonstrations of meta-learning in language modeling include filling in missing words with one-shot techniques, neural program induction and synthesis, and machine translation.
- Abstract Reasoning. This is a relatively new area in meta-learning which focuses on training models to solve more than just perception tasks. An example is solving the IQ test in the form of Raven’s Progressive Matrices.
Research at RealityEngines
Organizations that can benefit from machine learning often have access to large datasets, but the quality of that data can leave much to be desired. The datasets can be noisy, incomplete, and imbalanced. This either leads to a lot of time spent by data scientists on processing and cleaning the data, or an extremely sparse dataset which is insufficient for deep learning techniques.
At RealityEngines, we are experts at solving problems with sparse data available. Our service uses principles of meta-learning to create robust models even when you have a small number of training examples. You can find out about our approach on our research page.
- Improving Open-Source LLMs – Datasets, Merging and Stacking - January 11, 2024
- Open Source LLMs, Fine-Tunes and RAG Based Vector Store APIs - October 19, 2023
- Closing the Gap to Closed Source LLMs – 70B Giraffe 32k - September 25, 2023