

Pattern recognition is a crucial aspect of modern data analytics. These patterns can be studied to better understand the underlying structure of data and monitor behavior over time. However, there are often rare items or observations that seem to differ significantly from these patterns. These items are called anomalies (or outliers), and anomaly detection is the practice of identifying these rare items in order to understand what caused them. While some anomalies can be written off as random noise or insignificant glitches, a lot of important cases are related to bank fraud, cybersecurity issues, medical problems, malfunctioning equipment, and more.
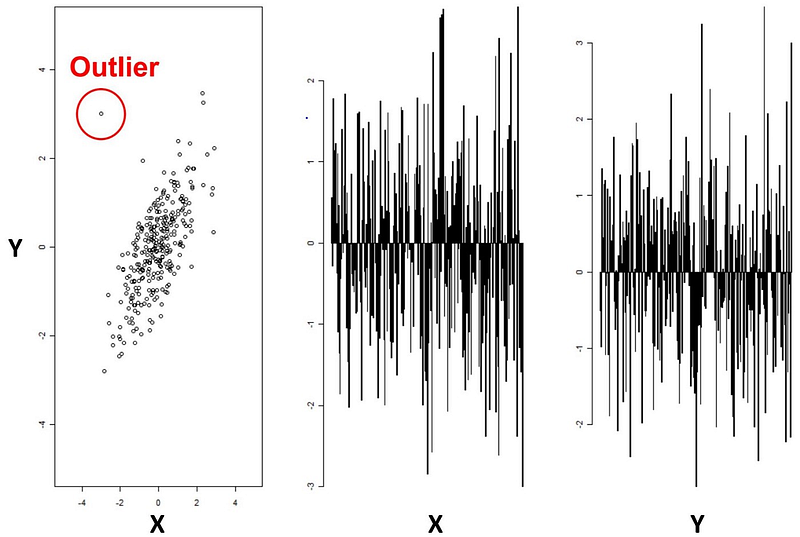
Let’s start with an example of two-dimensional data. In this case, the easiest way to detect the anomaly is by visualizing the set. Comparing the data on one dimension at a time won’t produce any results, but by looking at the problem with both parameters taken into account simultaneously, the outlier is clearly seen. This is a neat way to explain what anomaly detection is concerned with, but data in real-life scenarios can depend on tens or hundreds of parameters. When visualization is no longer an option, deep learning turns out to be a game-changer.
Deep Anomaly Detection
Many years of experience in the field of machine learning have shown that deep neural networks tend to significantly outperform traditional machine learning methods when an abundance of data is available.

There are many available deep learning techniques, each with their strengths and weaknesses. In the case of Deep Anomaly Detection (DAD), the algorithm of choice is usually defined by 3 key factors: the type of data being used,; the learning model; and the type of anomaly being detected.
Type of Data
Data can be broadly broken down into two categories: sequential (audio, text, etc.) and non-sequential (images, sensor data, etc.). The table below illustrates which models perform better in which case, where CNN stands for Convolutional Neural Network, RNN — Recurrent Neural Network, LSTM — Long Short Term Memory Network, and AE — Autoencoder. As studies have shown, deep learning models can learn complex feature relations on high-dimensional input data — the more layers, the better.

Type of Model
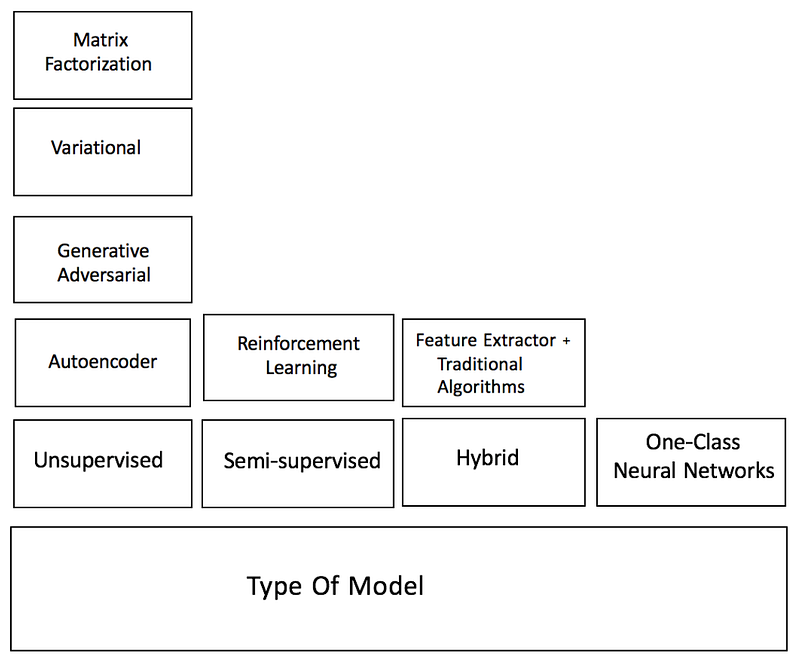
Methods for DAD algorithms can also be categorized by the kind of training model being used. Depending on the availability of labels, either semi-supervised or unsupervised learning is deployed.
- Semi-supervised learning is a much more popular option for anomaly detection than supervised learning since anomalies are rare events and there is often not enough labeled data to learn from. Labels for normal data, on the other hand, are much easier to acquire. Autoencoders have been shown to produce low reconstruction errors for normal instances over unusual events.
- Unsupervised models search for intrinsic patterns in the data and then determine which instances stray from these patterns. As we’ve already mentioned, labeled anomaly data is hard to obtain, and unsupervised models can be used to automatically produce these labels themselves. In addition, various unsupervised DAD models have been shown to outperform traditional machine learning methods such as principal component analysis, support vector machine, and Isolation Forest in applications such as healthcare and cybersecurity.
DAD techniques also differ based on the training objectives employed:
- Deep hybrid models mainly use autoencoders to perform feature extraction from images or sequences. These features can then be input to a traditional anomaly detection algorithm such as a one-class support vector machine (OC-SVM) to detect the outliers.
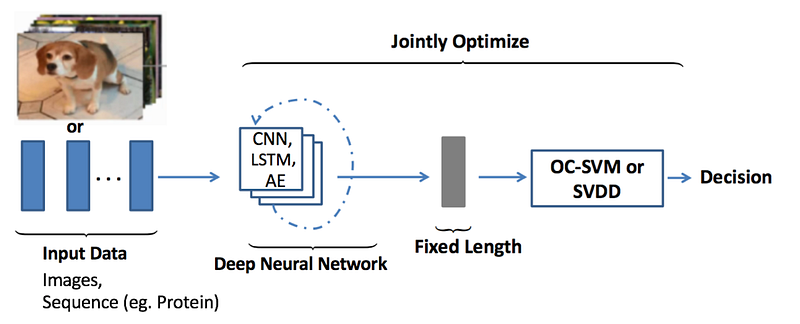
- One-Class Neural Networks (OC-NN) take a step forward by combining the ability of deep learning techniques to extract rich data representations with the objective of one-class algorithms to create a tight envelope surrounding the normal data. Other options include the usage of Deep Support Vector Data Description (DeepSVDD) to extract common variation factors by mapping the “normal” data to the center of a sphere.
Type of Anomaly
Broadly speaking, anomalies can be classified by three types: point, contextual, and group anomalies, with deep learning techniques demonstrating success in all three cases.
- Point anomalies often represent single irregularities that could have happened randomly and may have no deeper meaning behind them. For example, an unusually high transaction at a restaurant is considered a point anomaly.
- Contextual anomalies are labeled as such only under specific circumstances, in a certain context. Usually, these contextual features are space and time. For example, a temperature of 32°F is considered normal in winter, but in July this would be considered an anomaly. Long Short-Term Memory models have been successfully used to identify anomalies in a given context.
- Lastly, group anomalies are groups of data points that would be considered normal if observed in isolation, but as a group causes suspicion. We can once again relate to the transaction example — a single Mobil Mart purchase of $75 doesn’t raise any questions, but several of them over a short time frame would be considered a group anomaly. In the case of non-sequential data, autoencoder models have been useful in detecting irregular groups of pixels in images.

Once the DAD model has finished its learning, its output for data can be either a label (“normal”, “anomaly”) or a ranking score, showing exactly “how anomalous” a certain data point is.
Real-Time Anomaly Detection in Big Data
Perhaps the main drivers of interest behind DAD techniques are real-time applications for Big Data. There are many scenarios when data has to be analyzed on the fly since doing it offline would either produce no results whatsoever or even cause certain losses. These scenarios usually deal with vast amounts of quickly changing data in a complex environment. Due to the scalability of neural networks, deep learning techniques are a perfect fit for this task.
Cybersecurity
According to Cisco, 2.3 Zettabytes of IP traffic will go through the Internet in 2020, a 62% increase compared to 2015. In addition to that, most of the traffic (71%) will be going through less secure non-PC devices such as tablets, smart TVs, consoles, and various IoT devices. This is a growing concern for cybersecurity since all of this traffic needs to be monitored in real-time to prevent potential hacks. Intrusion detection is a primary application of anomaly detection since malicious activity tends to look irregular in comparison to everyday operations.
Fraud Detection
Fraud can happen in many areas, including telecoms, healthcare, banking, and insurance. Traditional machine learning algorithms have been used in fraud detection, but once again difficulties arise when the detection needs to happen immediately. A prime example is insider trading. Data in stock markets changes over the span of milliseconds and anomaly detection has already been successfully used to detect insider trading fraud. In this case, real-time monitoring is necessary to prevent people from making illegal profits.
Autonomous Vehicles and other IoT applications
Safety is the most important concern of the autonomous vehicle industry. Data from cameras and internal sensors needs to be continuously monitored in order to prevent potential car accidents, or in less severe cases — prevent unnecessary traffic jams.
Healthcare
Medical monitoring services require constant attention so that a response to sudden changes in a patient’s vital signals can happen in a timely manner. Additionally, anomaly detection can be applied to medical images in order to help diagnose diseases.

Other Safety-Critical Systems
Any systems where a malfunction could lead to heavy financial losses or even health hazards can benefit from timely anomaly detection. Areas include monitors for electricity infrastructure, signals from fire alarms, railway signaling and control, air traffic control, and more.
Anomaly Detection from RealityEngines
RealityEngines provides you with state-of-the-art Fraud and Security solutions such as:
- Account Takeover and Defense. Shield your customers by preventing malicious insiders, bots, and bad actors from taking over accounts.
- Transaction Fraud. Feel confident in accepting payments by detecting transaction fraud as it happens.
- Intelligent Threat Detection. Continuously monitor your environment for malicious activity and stop breachers in their tracks.
Setup is simple and takes only a few hours — no Machine Learning expertise required from your end. Be sure to check out our website for more information.
- Improving Open-Source LLMs – Datasets, Merging and Stacking - January 11, 2024
- Open Source LLMs, Fine-Tunes and RAG Based Vector Store APIs - October 19, 2023
- Closing the Gap to Closed Source LLMs – 70B Giraffe 32k - September 25, 2023