

The painting “Edmond de Belamy” is an AI-generated portrait that was sold at an auction for $432,500 in 2018. That’s a lot of money for an artificial painting, but how exactly was it created? Back in 2014, a research team at the University of Montreal published a paper introducing what would soon be called “the coolest idea in machine learning in the last twenty years” — Generative Adversarial Networks (GANs). In a game-like fashion, two learning models — the generator and discriminator — are pitted against each other. The result of this battle is the ability to create new, synthetic data similar to the training input. The portrait is an example of artwork created using this very approach.
For a long time, deep learning found its biggest success in classification problems, when a rich high-dimensional input (such as an image) needed to be labeled according to its contents. The opposite problem, i.e. generating content corresponding to a label of some sort (like an image of a cat), is much more difficult, but with the onset of GANs, has become a very hot topic in machine learning over the last few years.
Generator vs Discriminator
Unlike most machine learning approaches, where a single model receives training data from which it learns, GANs involve two different models that teach each other in an adversarial process. The generator, given a random noise vector, creates synthetic data and the discriminator divides that artificial result from “true” data in the training set.
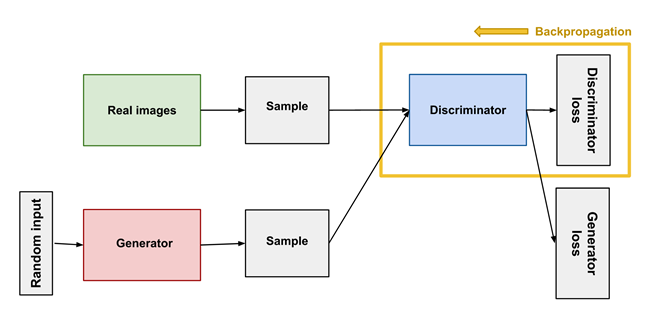
In the process of learning, the goal of the generator is to produce content that the discriminator will not be able to distinguish from real data. The generator aims to confuse the discriminator as much as possible and maximize its error. A competition between counterfeiters and police is often brought up as an analogy. The counterfeiters aim to produce coins indistinguishable from real ones, while the police don’t want to let any fake money pass through. Because of the competition, both parties enhance their skills until the police can’t discern what’s real and what’s fake.
The contest between the two parties operates in terms of data distributions. Let’s imagine the goal of the GAN is to generate new pictures of dogs. In a simple case of black and white images of size n x n pixels. Each image can be stored as a vector of size N = n x n. In this vector space, some images strongly resemble dogs, however, the vast majority doesn’t. We can say that there is a probability distribution across the vector space, indicating the likelihood that a certain vector represents a dog. The vector space is gigantic and the distribution is unknown to us. However, through the process of learning the generator can create random images (“vectors”) that look more and more like a real dog.
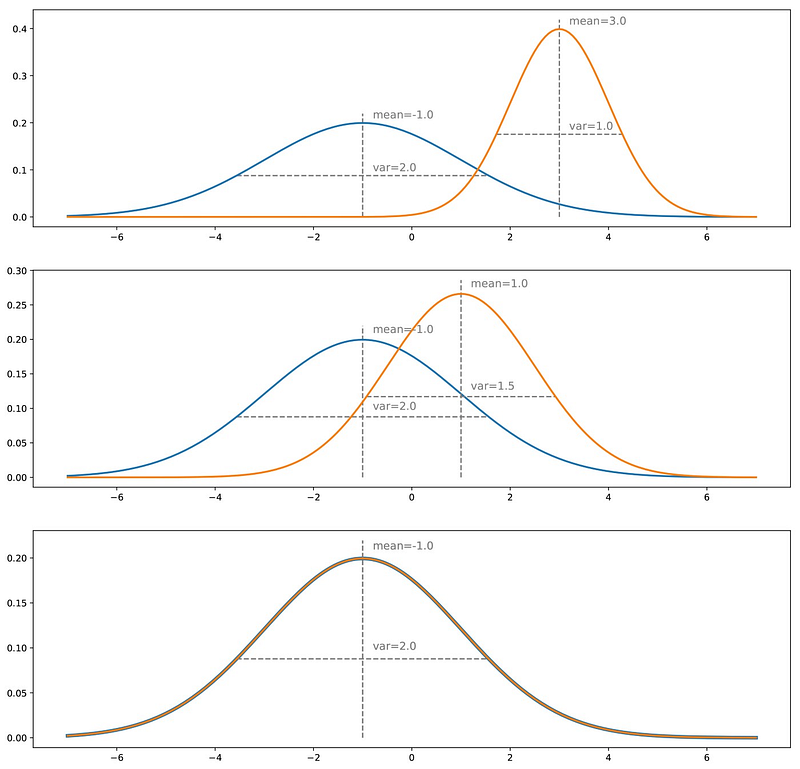
At the very start, we have a “true” distribution based on the training data and an initial distribution which the generator achieved by pre-training on random inputs. Once the synthetic data has been passed over to the discriminator, the error, i.e. the difference in the two distributions, is backpropagated to the generator. This adjusts its weights accordingly and makes a step of gradient descent to lower the “distance” between the distributions. Ideally, over time the generated distribution becomes indistinguishable from the real one, which means the generator is capable of creating brand new and realistic content (as if the Internet didn’t have enough dog images already).
GAN Applications
Despite appearing only a few years ago, GANs have rapidly found multiple applications.
Fashion
Image generation is where GANs shine the most, and fashion is no exception. For example, GANs can be used to create imaginary models, cutting down on costs of hiring a real one. Already there are “fully virtual” models such as Miquela, who has over 2M followers on her Instagram. Another upside is enhanced diversity in models, which means that marketing campaigns can better target specific consumer groups.
Science & Healthcare
Astronomical images are often very noisy because of the number of extraneous sources in the sky. GANs have been used to improve the images, clearing out previously unattainable details. GANs have also found their uses in healthcare, like automatically detecting glaucoma at an early stage.

Others
GANs can also up-scale images from old video games and give them a fresh look, reconstruct 3D models of objects from photos, age faces, and more.
GANs and dataset augmentation
A more novel application is related to the topic of data augmentation. By far one of the most important conditions for a neural network to train well is the availability of lots of quality data. However, in some cases the available data is scarce. In healthcare, for example, a lot of information is private, which limits the capabilities of models to train and achieve higher accuracy.
There are several ways of augmenting the current dataset that a model already has at its disposal. In the case of images, you can simply flip and/or rotate the image in various ways. If the image has a cat, after those transformations it will still have one, but it will be a different picture you can train your model on.

For many other types of data such as tabular data, it is not obvious how to significantly augment a datapoint while keeping it in the same class. However, we can use GANs to augment this type of data.
Overview of DAGAN — dataset augmentation GAN
A Data Augmentation GAN (DAGAN) works in a similar way to regular GANs. However, instead of feeding random inputs to the generator, a DAGAN takes original data and adds a noise vector to it, which essentially performs the role of a transformation.

In this approach, the generator is focused not on creating new data from scratch, but rather changing the existing data in a way that keeps itin the same class. The discriminator, on the other hand, must discriminate between two real images from the same class, or a real image and an augmented image. Therefore, the generator cannot make small transformations, or transformations that push the image outside of its class. One research paper presented improvements for few-shot meta-learning systems based on datasets from Omniglot (an improvement from 69% to 82%), EMNIST (73.9% to 75%), and VGG-FACE (4.5% to 125).

DAGANs have already found applications in areas such as CT scan segmentation, increasing the performance of a Convolutional Neural Network in liver lesion classification, and brain segmentation tasks.
RealityEngines and Synthetic data
Over at RealityEngines, we have developed state-of-the-art GANs to help out those businesses that need the help of AI but don’t have the necessary resources. When solving niche problems a lack of data is a frequent issue. However, it can be overcome by creating new, synthetic data. In our tests, we have created models that are up to 15% more accurate when trained with the generated data. For more information, be sure to check out our website.
- Improving Open-Source LLMs – Datasets, Merging and Stacking - January 11, 2024
- Open Source LLMs, Fine-Tunes and RAG Based Vector Store APIs - October 19, 2023
- Closing the Gap to Closed Source LLMs – 70B Giraffe 32k - September 25, 2023